- Oncosoft and AuraCare Form Strategic Partnership to Launch ‘OncoVET’
- Oncosoft Joins Science & Technology Innovation Fund IR Event
- Showcasing OncoStudio’s Clinical Success in Japan at JCERG 2026
- RSS 2026 Participation: Presenting LLM-Based Target Contouring Research
- [Upcoming Events]
The 71st KSMP Spring Meeting
ITEM 2026
2026 KOSRT Spring Conference
- [Column] News in RadOnc
|
|
|
❶ Oncosoft and AuraCare Form Strategic Partnership to Launch ‘OncoVET’ |
|
|
Oncosoft has signed a strategic partnership with AuraCare, a leading developer of domestic veterinary radiotherapy devices, to officially launch OncoVET—an AI-powered auto-contouring system designed for veterinary radiation therapy planning.
OncoVET leverages Oncosoft’s advanced AI technology to automatically segment organs and lesions in animal patients. This solution significantly enhances accuracy and consistency while drastically reducing processing time compared to traditional manual workflows. The core technology, OncoStudio, has already established a strong clinical reputation in human medicine, supporting over 200 organs and Clinical Target Volumes (CTV). OncoVET builds on this proven foundation, specifically optimized with veterinary clinical data.
Meanwhile, AuraCare has successfully commercialized ‘LEP300,’ a specialized radiation therapy device for pets. Through this collaboration, the two companies are now ready to provide veterinary hospitals with a comprehensive solution that integrates both hardware and software. Moving forward, they plan to expand their presence in the Korean market and jointly pursue global expansion, with a primary focus on the United States. |
|
|
❷ Oncosoft Joins Science & Technology Innovation Fund IR Event |
|
|
Oncosoft participated in the “Science & Tech R&D Innovative Enterprise IR & Matching Day,” hosted by Shinhan Asset Management, to engage with leading investment networks.
This event was part of the Science & Technology Innovation Fund, which was created to invest in national strategic technologies and companies focused on tech-commercialization. It provided a platform for promising ventures to connect with sub-fund managers. Oncosoft showcased its core technologies and growth strategies, exploring business expansion possibilities through 1:1 consultations with major investors, including Helios PE, Premier Partners, BNH Investment, and Bluepoint Partners.
This participation allowed Oncosoft to validate its technological and business direction from an investor's perspective while further solidifying its mid-to-long-term growth strategy.
|
|
|
❶ Showcasing OncoStudio’s Clinical Success in Japan at JCERG 2026 |
|
|
On March 14, Oncosoft attended JCERG 2026 in Tokyo, Japan, showcasing OncoStudio alongside its local partner, Anzai Medical. Through booth demonstrations and a sponsored seminar, the company shared detailed clinical outcomes and technical milestones achieved by OncoStudio.
During the seminar, Professor Nemoto from Yamanashi University presented a comparative study of over 10 different auto-contouring software programs. In his evaluation, OncoStudio consistently ranked at the top for accuracy, shape consistency, and processing speed, proving its high reliability in real-world clinical environments.
Furthermore, Professor Nozawa from the University of Tokyo discussed the practical improvements OncoStudio has brought to healthcare settings. He emphasized how the system significantly shortens treatment planning time and shared cases where clinical applications were expanded through MRI-based contouring and CT-MR registration. At the booth, attendees experienced live demonstrations of the AI contouring and AI Agent features. Active discussions on high-level clinical applications—such as Space OAR, 4D CT, and CT-MR fusion—highlighted the growing adoption of OncoStudio in the Japanese market. |
|
|
❷ RSS 2026 Participation: Presenting LLM-Based Target Contouring Research
|
|
|
Oncosoft participated in RSS 2026 in Orlando, USA, to present its groundbreaking research on Target Contouring using Large Language Models (LLMs). CEO Jin Sung Kim shared the latest findings on applying AI to tumor target areas—the most critical and complex part of radiation therapy planning.
While conventional AI segmentation has primarily focused on Organs at Risk (OARs) with consistent anatomical shapes, this research is a major milestone as it expands AI’s reach to tumor targets, which are notoriously difficult to automate due to high patient variability. By utilizing a multimodal AI approach that integrates imaging data with Electronic Medical Records (EMR) and clinical text, Oncosoft demonstrated that AI can mimic a physician's clinical reasoning for more precise target definition.
The company also introduced MoME (Mixture of Multicenter Experts) technology, which learns and reflects the unique treatment strategies and contouring styles of different institutions and physicians. This suggests a future for personalized, tailor-made solutions in clinical settings. Furthermore, the presentation featured an "AI Agent" concept capable of interpreting clinical guidelines to generate target contours, showcasing a new era of end-to-end automation in radiation therapy.
|
|
|
❶ The 71st Korean Society of Medical Physics (KSMP) Spring Meeting |
|
|
- Date: April 10 (Fri) – 11 (Sat), 2026
- Venue: SETEC Convention Center
- Format: Offline
|
|
|
📍Abstract Submission & Pre-registration Schedule
- Abstract Submission Deadline: March 20 (Fri), 2026
- Review Results Notification: March 30 (Mon), 2026
- Early Registration Deadline: March 31 (Tue), 2026
|
|
|
Oncosoft will participate in ITEM 2026 from April 17 to 19. As Japan’s premier exhibition for medical imaging and radiology, ITEM is a key platform for global leaders and medical institutions. Oncosoft will showcase its AI auto-contouring technology and clinical applications, incorporating feedback from experts at JCERG 2026 to further refine its workflows and expand its operations in Japan through local partnerships. |
|
|
❸ 2026 Korean Society of Radiotherapeutic Technologists (KOSRT) Spring Conference
|
|
|
- Date: April 25 (Sat), 2026, 13:00–17:00
- Venue: Auditorium, Gangneung Asan Hospital
|
|
|
✅ Is LLM a Good Tool for Everyone?
Not long ago, a family member of mine fell ill. When the symptoms persisted for over a week without a clear cause, I began inputting the details into an LLM to start a dialogue. To my surprise, a very rare disease was suggested as the primary differential diagnosis almost every time. I was skeptical at first, but that diagnosis turned out to be correct. From that point on, the LLM continued to be a valuable resource—summarizing the latest treatment guidelines, assisting in the process of switching doctors and hospitals, and allowing us to respond quickly when signs of complications appeared. I felt deeply grateful to have such a reliable assistant by my side.
However, back in my consultation room, I witness a completely different scene.
There is a young patient whom the entire medical staff finds difficult to treat. This patient blindly trusts information from the LLM, repeatedly contradicting the medical team’s opinions and insisting only on the treatment path suggested by the AI. The trust between the patient and the clinicians was broken long ago. Furthermore, in recent hospital conferences, I sometimes see presenters reading from scripts with beautifully organized slides generated by LLMs. Yet, when asked about the core content, they often lack a sufficient understanding of what they are presenting.
Why does the same tool yield such drastically different results? A study published this past February in Nature Medicine provides a compelling answer to this question. |
|
|
✅ Study Design
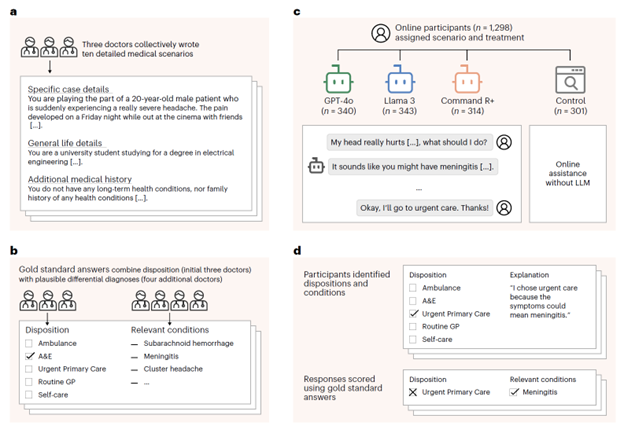
A research team from the Oxford Internet Institute conducted a Randomized Controlled Trial (RCT) to verify the medical reliability of LLMs among the general public. Instead of a standard benchmark test, they created a real-world scenario where individuals had to make medical decisions through interactions with an LLM.
Three physicians collaborated to develop 10 medical scenarios, establishing "gold standard" diagnoses and dispositions (ranging from calling an ambulance to self-care across five levels). They randomly assigned 1,298 British adults to four groups:
- GPT-4o Group (n=340)
- Llama 3 Group (n=343)
- Command R+ Group (n=314) – A model that augments web searches.
- Control Group (n=301) – Used standard internet searches without an LLM.
After interacting with their assigned tool, participants answered which medical service they would use and what condition they suspected. |
|
|
✅ LLMs Excel Alone, but Falter with Humans
The results of this study can be summarized in one sentence:
"LLMs pass exams with flying colors, but their performance plummets when used by humans."
When the LLMs processed the scenarios independently, their performance was impressive, correctly identifying related diseases in 94.9% of cases and appropriate dispositions in 56.3%. However, when real people used the LLMs, the accuracy for identifying diseases dropped below 34.5%, and disposition accuracy fell below 44.2%. Even more shocking was that all three LLM groups performed worse at identifying diseases than the control group, who only used standard internet searches.
|
|
|
✅ Why Does This Happen?
The research team analyzed 30 actual conversation transcripts and identified three primary causes for these failures:
-
Incomplete Information: In over half of the failed cases, participants began the conversation by omitting key symptoms. Just as a doctor systematically takes a patient's history, an LLM requires accurate input to provide an accurate output. General users are often unfamiliar with this process.
-
Confirmation Bias: Even when the LLM provided the correct information, users often failed to follow it. While LLMs mentioned the correct disease in 65–73% of conversations, that information was reflected in the participants' final answers at a much lower rate. Users who had already reached their own conclusions tended to ignore the AI's recommendations—much like the patient I mentioned earlier, who selectively accepts only what they want to hear.
-
Input Sensitivity: LLMs sometimes added incorrect information or gave contradictory advice to two users describing the same symptoms due to subtle differences in how they phrased their input.
|
|
|
✅ Benchmarks Fail to Predict Real-World Failure
The study found no significant correlation between an LLM’s score on MedQA (Medical Licensing Exam benchmarks) and its actual performance in interactive experiments. In other words, doing well on a test does not mean it will be used well in practice.
Even more interesting was the "simulated patient" experiment, where LLMs acted as patients to talk to other LLMs. These simulations also failed to predict human-involved results because the simulated patients provided information much more systematically and consistently than real people. AI has yet to replicate how ambiguously, emotionally, and incompletely a real human explains their symptoms.
|
|
|
✅ Does the LLM Help or Hinder Healthcare?
Reading this paper reaffirmed my belief that the answer depends entirely on the person using it.
The reason the LLM was helpful when my family was sick was that I possessed the necessary medical background. Because I have spent years reading papers, attending conferences, and writing and reviewing peer-reviewed research, I had a framework for critical thinking. This allowed me to filter the AI's responses rather than accepting them blindly. I also knew how to provide symptom information systematically. Conversely, for a layperson without medical knowledge or a junior doctor who hasn't yet built that critical framework, an LLM can inadvertently plant errors.
The study’s conclusion points in the same direction. The problem with LLMs isn't a lack of knowledge; it's that humans struggle to extract and utilize that knowledge correctly. Between a user with medical background and critical thinking skills and one without, the same LLM functions entirely differently.
The authors emphasize that before medical AI is publicly deployed, it must undergo safety testing with real people—benchmarks and simulations are not enough. I would take this a step further: user education and literacy must be considered as part of the design process. Just as a high-end auto-contouring system is dangerous without a skilled physician to critically review the results, an LLM only functions correctly in the hands of someone who knows how to use it.
The software we develop at Oncosoft faces the same question. Considering who will use it, in what context, and how, right from the design stage—that will ultimately be the difference between a good AI medical tool and a poor one.
(This article was drafted by the author, refined with the assistance of Claude AI, and finally reviewed and edited by the author.)
|
|
|
|